
Benchmarking Bionetta
Introducing Bionetta, an R1CS-based proving framework designed with a focus on client-side proving and on-chain verification of neural network architectures. Our goal was to create a framework with (a) proof and verification key sizes as small as possible, suitable for on-chain deployment, and (b) superior proving time that does not consume too much RAM. Currently, Groth16 is one of the best choices, providing constant-sized proof and verification time, relatively small verification key sizes, well-developed infrastructure, and, as we discovered, R1CS arithmetization that is much more suitable for client-side proving than PlonK-based approaches such as Halo2.
While initially the framework was designed primarily for custom-crafted biometric neural networks for production purposes, we discovered that our approach generalizes admirably well to general neural network architectures. Тhat said, we share the benchmark results and compare them to the results of other frameworks in a selected pool of models for fair results. The results of our framework show an incredible boost in the majority of the criteria above and enable fast and easy flow for deploying client-side zkML on-chain.
Note: Our approach not only boosts the proving and verification performance for existing neural network architectures, but also discovers the way how to build custom architectures to make proving even faster. However, this is a topic for yet another blog!
Similar Approaches
We’ve chosen the four most widely used and well-developed zkML frameworks — EZKL, keras2circom, *ddkang/zkml,* and *deep-prove — to compare and benchmark with Bionetta*. Let's describe the differences between each of these frameworks and Bionetta.
EZKL and ddkang/zkml rely on Halo2 proving system and PlonKish arithmetization, which is not as optimal as R1CS, when it comes to the client-side proving (when the model architecture and weights are public, resulting in a drastically large number of gates). Also, Groth16 provides much better verification key sizes (3KB vs 650KB up to 4.2MB).
keras2circom translates Keras-based models into Circom circuits, but cannot handle deep networks, where the scaling factor of each weight cannot be more significant than the estimated value of 10⌃76/ℓ (ℓ is the depth of the neural network), which causes the loss of precision. Also, keras2circom provides less optimal circuits when the weights are public.
Deep-prove relies on Ceno, a GKR-based protocol. Deep-prove has linear proving time in contrast to linear-logarithmic proving time in other proving systems. However, there is one considerable downside: the size of the proof. It can be more than several megabytes, making it completely useless for applications where the size of the data matters the most, like in smart-contract applications. Also, there is another massive issue with deep-prove — standard 8-bit quantization, which messes up the accuracy of the resulting output of the circuit, where this output rarely coincides with the real outputs of the model. Making the quantization bits higher makes the proof size much bigger and impractical for applications.
While comparing the mentioned zkML frameworks and Bionetta, we relied on four main criteria:
- An ability to use a framework for client-side proving without waiting more than 10 minutes to prove.
- Verifiability on-chain: the cheaper the verifier, the better.
- Support for generic architectures: the current framework infrastructure supports any Tensorflow/PyTorch models and allows for compiling ZK circuits on top of them.
- Consistency: the equivalence of outputs in the original and ZK models.
In Table 1, there is a summary of framework capabilities by the mentioned criteria.

Table 1: Comparison of capabilities of different zkML frameworks.
Results of Benchmarking Frameworks
Setup
For the benchmarking setup, we used seven models with different numbers of parameters and activations. To make the comparison fair, we use only Dense layers with ReLU activations (recall that ReLU(x)=max(0,x)), which is the foundation of most modern architectures.
Models are designed as follows:
- Model 1 is minimal and has a lot of linear components with only a single hidden layer to test whether the framework works.
- For Model 2 and Model 3, we put only 10 non-linearity calls, but many linear operations (such as large matrix multiplications).
- The Model 4 and Model 5 are the opposite: several thousands of non-linearity calls with the (relatively) insignificant number of linear operations.
- The last models (6 and 7) have many linearities and activations, representing the realistic setup in production.
The input is a 28×28 grayscale image flattened and perceived as a vector of size 784. Table 2 contains specifications for each model (number of parameters and activations). The Model 1 parameters were chosen explicitly to test all frameworks in the easiest case. Models 2 and 3 are extreme cases when Bionetta operates better than other frameworks. Models 4 and 5 are the opposite in results for our framework. The last two models provide a realistic setup with a balance between a number of parameters and activations.
For system settings, we used: TensorFlow 2.12 for Bionetta and TensorFlow/PyTorch versions based on the framework. For hardware and operating systems, 2.6 GHz 6-Core Intel Core i7, 16 GB RAM, and macOS version 15.3.1.

Table 2: Models used for benchmarking.
Results of Benchmarking
Memory requirements
Let's start with the memory requirements. Tables 3, 4, and 5 present data on proof, proving key, and verification key sizes for models and testing selected frameworks.

Table 3: Proof size, KB

Table 4: Proving key size, KB. In deep-prove there is no proving key. ❌ means that the model couldn't have been compiled in reasonable time (in 6 hours) or RAM usage.

Table 5: Verification key size, KB. In deep-prove there is no verification key.
Proving and Verification complexity
Now, we will present the results of proving, witness generation, and verification times for models in Tables 6, 7, and 8.

Table 6: Proving time, s

Table 7: Witness generation time, s1

Table 8: Verification time, s *since these models have not been compiled, we provide the estimates.
Compilation and Setup Time
In this section, we will present the results of compilation and setup times in Tables 9 and 10.

Table 9: Compilation time, s

Table 10: Setup time, s
Analysis
Memory requirements
As we can see from the results, Groth16 has the smallest verification keys among other systems, making it easy to integrate with smart contracts. We can see similar results in the proof size and proving keys. Below are the bar plot visualizations of the results



Proving and Verification
In Groth16, the proof verification takes constant time and is slower than Halo2 on small circuits, but it can be easily scaled for arbitrary-sized models. Note that ddkang/zkml have the smallest verification time with a verification key that isn't that large, making it a good candidate for on-chain verification. Also, deep-prove is the second by time comparison, but isn’t practical enough for the majority of blockchain applications due to the overwhelmingly large proof size.

The generation time of the witness is compared to the generation time of other frameworks. This is because of the custom witness generator built into the framework architecture. Deep-prove outperforms all frameworks with significantly less time.

Proving time in Bionetta is better than in other frameworks, except for deep-prove. For example, for Model 6, proving time in Bionetta is 8.9 times less than proving time in keras2circom, 6.1 times less than proving time in EZKL, and 2.4 times less than proving time in ddkang/zkml. For Model 3, which is highly linear, we can see that our framework gives us 237, 421, and 86 times better results than keras2circom, EZKL, and ddkang/zkml, respectively.
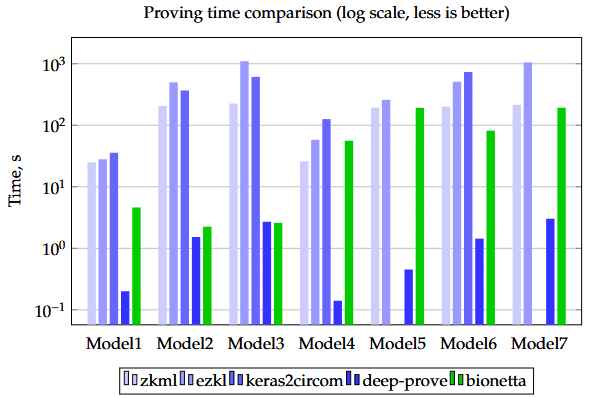
As we can see, Bionetta performs best when the model is highly linear. Because of this, choosing the right architecture that exploits numerous large matrix products results in a surprising boost in proving time.
Compilation and Setup Time
The main issue with Bionetta is the circuit compilation process. For Bionetta, it can be 2000 times longer than the one provided by EZKL or ddkang/zkml for the same model.
However, it is not a serious issue for the user because compilation is done only once (per model) by developers.


Conclusion
We presented a new framework for zero-knowledge machine learning, named Bionetta. Experiments have shown that the framework can prove and verify machine learning models fast with high accuracy and low cost.
After comparing our framework with chosen frameworks, such as EZKL, ddkang/zkml, and keras2circom, we can conclude that Bionetta outperforms them in terms of proof size, verification key, and proving time while having a reasonable verification procedure that is fully compatible with Ethereum smart contracts.
There is room for optimizing and modifying the implemented framework for better results. Our future goal is to:
- Create a custom Groth-based protocol for Bionetta, allowing us to achieve better performance and lower cost per non-linear activation.
- Implement more efficient compilation and setup procedures for better compilation and setup times, making the framework more user-friendly.
- The last thing: make Bionetta open-sourced and available for public use, allowing researchers and developers to use our work to build on and contribute to the development of zero-knowledge machine learning.